7 mins
Black Friday Brilliance: Managing a Billion Transactions Through Tactics & Teamwork
 Jamie Coleman, Senior Developer Relations Engineer at GBG Loqate
Jamie Coleman, Senior Developer Relations Engineer at GBG Loqate

The Black Friday period is one of the busiest times in the retail calendar, and Loqate customers rely on our infrastructure to support their businesses at this crucial time. Over the last 10 years we’ve seen our request volume increase massively - during this period in 2023 we processed over 1 billion API requests, with greater than 99.99% availability - and managing this requires the right technologies, careful planning, and a great team of people.
In this article I’ll talk you through how here at Loqate we scale our infrastructure on different clouds, including the technologies and processes that are in place, and some of the problems we have had to overcome in the past. I’ll also give some insights into how the team works together over this busy period to keep everything running smoothly.
Black Friday madness
The term ‘Black Friday’ was coined way back in 1869 for the financial crisis in the USA. Since then, it has gone through various iterations, with the modern term coming into use in the 1980s to denote the unofficial start of the Christmas shopping period – i.e. when retailers shift from the red (making a loss) to black (making a profit).
Here at Loqate, the Black Friday period – which now includes Cyber Monday – is unquestionably our busiest time of the year. We all know it’s nearly time for Black Friday, not by all the adverts for upcoming sales, but because we have a series of processes that start months before the busy weekend to help make sure all our services are performing with low latency and zero downtime. With some of the world’s biggest retailers and partners relying on our services – including Fedex, Oracle and IBM just to name a few – we all need to be on top of our game.
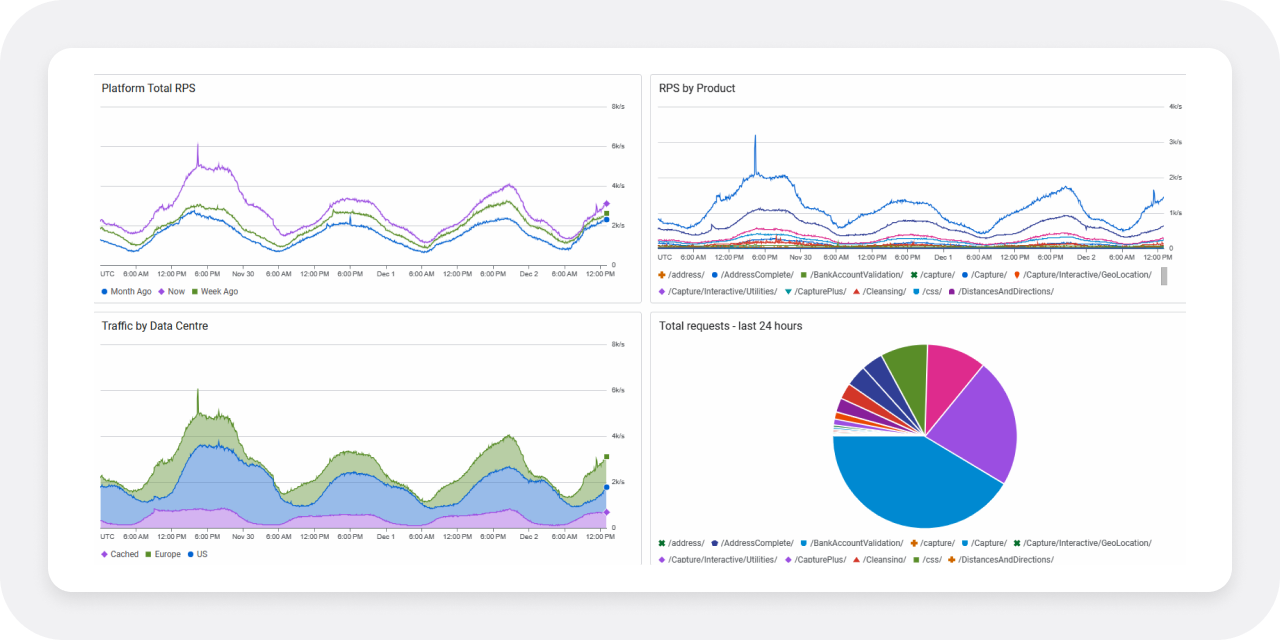
Interestingly, while Black Friday was once a USA-focused period, that’s now very much not the case. As you can see from some of our traffic metrics below, we now have more traffic going to our European data centre over this period than our US one.
The era of the cloud
The era of the cloud has come upon us at an incredible pace. If you’ve always worked for a young (post-2015), modern tech company then you might never have experienced the magic of running your own data centre. Back in 2013 when I started my career, public clouds were considered risky for large enterprises due to reliability and security concerns. Even the big names like Oracle and IBM were only just getting into the cloud game.
Now, basically everything enterprise runs on a cloud - or is planned to be moved over at some point in the future. For all the tactile satisfaction of physical hardware, running anything on-prem comes with challenges that modern cloud providers all take care of themselves. The costs of all those additional concerns - hardware maintenance and upgrades, latency issues, power outages, security and reliability - come at a huge cost to large enterprises, so having someone else deal with them is generally far more cost effective than the old on-prem model.
While many of us will be familiar with an unexpected cloud bill due to leaving services running, it’s the simplicity and (nowadays) reliability of what the cloud provides that has drawn in enterprise customers. That’s certainly the case for Loqate - we’re fully committed to the cloud model, and we’ve been moving our tech stack over to the cloud for the last nine years!
We do still have a last few pieces of on-prem estate (which I think is normal for a nearly 25-year-old company), but over the next few years we have a plan to shut down our last remaining on-prem systems. These are old, legacy services that we want to turn off but are still used by a few self-serve customers. Moving them to the cloud doesn’t make sense considering their age, the cost of such a move, and the upgrades required to make them maintainable in a cloud architecture.
Preparation for the Big Weekend
As I write this article in September, Loqate engineers are already planning for Black Friday! Even though we start specific work for Black Friday three months out, we run product and platform load testing throughout the year just to make sure we don’t get any nasty surprises. Especially with our bigger customers, there are some huge unknowns including the overall capacity requirements of our APIs, and how much traffic might increase over a period like Black Friday, so regular testing is a real priority for us.
Of course, the proof is in the pudding. Do I hear Christmas music already?
Let’s take a look at what happens as Black Friday gets closer, though.
Three months prior
This is when we start ramping up our platform testing, specifically looking at things like the throughput and stability of our cloud infrastructure components (i.e. web servers, load balancers and database servers, etc.).
In terms of product load testing, we take our average load throughout the year (minus the Black Friday weekend) and test the load up to six times that number. The thinking behind this is that over the Black Friday period we regularly see double our normal traffic. If a data centre fails, of course one of the others (we have three in total) can pick up the traffic, but in that instance we need to be sure that each data centre can handle up to three times its normal, expected traffic.
Let’s go into a bit more detail on what these tests actually involve.
Most of our customers will be familiar with our Address Capture and Address Verify services, but we also off a range of other services such as Phone, Email and Bank validation to name a few. Not all these APIs are likely to be hit harder than usual during the Black Friday period, so the first step is to identify which APIs are in scope. The second step is to identify the different loading profiles per region, and the third is to find a baseline of peak loads for each API. The technical process goes a little something like this:
- Identify in scope APIs
- Find the normal average load and predicted peak load
- Validate first with our staging environment
- Spin up K6 operator called load store mimicking external traffic
- Scale up K6 cluster to generate more load
- Ramp up in 5-10 min intervals (due to service startup times)
- Keep the threshold at ~51% to all new services to start up
- Run a final load test for around 50mins at 6x capacity
- Load test the whole platform (all APIs at once)
One thing to consider here is that we need to be constantly checking the logs for any memory leaks. Bear in mind, most cloud providers can take a while (often up to 30 seconds in our case) to alert about any issues. This is particularly important if you also test on your production environment, like we do!
Two weeks prior
At two weeks before Black Friday, we usually put a code freeze on the in-scope APIs. As traffic starts to increase over the next fortnight, we then manually scale the in-scope services in the run-up to Black Friday itself. You might wonder why we don’t rely on the cloud’s autoscaling capabilities, rather than manually scaling. The answer is that we do!
Throughout the year we normally rely on the cloud to auto scale our services, but as we have some legacy systems in VMs that are yet to be moved into a micro-service architecture (or into containers), they can take a while to spin up. Normally this isn’t a problem, as they are resilient enough to handle spikes in load until more come online. Over the Black Friday period however, we see massive spikes in traffic throughout the day, so to avoid any possibility of latency issues, we simply spin up extra services and absorb the extra costs.
It's worth the cost to us to do this, as the Black Friday period is such an important time of the year for our e-commerce customers.
If you’re interested, most of what we pre-scale up are things like web servers and databases.
One to two days prior
With Black Friday looming, some of our engineers are keeping very busy with last minute preparations. One of the main considerations at this point is some last-minute testing to make sure that if a data centre fails, the others can pick up the extra traffic with minimal – or ideally, no - latency issues. We run these last tests a few days prior to Black Friday, to make sure nothing has changed in the platform environment. We then defer most other things - like database maintenance, updates to our data, and unessential jobs - until after the weekend, just to be safe.
It's not all about the technology, though. Throughout all these processes one of the most crucial tasks is to keep our support team informed. At Loqate, they are part of our engineering organisation and are the front line to the customer. If anything goes wrong, they need to be able to help and give our customers the information they need.
Our tech stack
Being a 24-year-old company that has gone through a few transformations over the years, you can imagine we have a rather - let’s say “hybrid” - technology stack. Luckily, most of it is in just a few languages (Nodejs, Go & .Net) and now most of it has moved to the cloud. Some of our partners, such as IBM and Oracle, run on-prem versions of our services on their own clouds, but with just a few exceptions we mainly have everything running on a single cloud.
We essentially have a 3 tier web applications and one main monolith funnily enough called “services”, all backed by a webDB that is being moved to MongoDB. At one point we had over 1,200 services running, but with lots of great work in consolidating our stack and moving customers to new versions of our APIs, we are now down to around 400.
Overcoming challenges
Over the years we have had a few issues to overcome, mostly around scalability and issues with our web server stack. We've addressed these by adding a lot of automation to the web layer, letting us scale rapidly on demand. We've also done a lot of work to decouple elements that were previous strongly linked, like adding a caching layer to our usage system between the web servers and SQL.
The last time we had a major issue on Black Friday was in 2020. Let’s have a quick look at what happened.
Firstly, our onsite data centre in the US crashed due to an auto scaling issue. As a result, all our US traffic got re-routed to our on-prem European datacentre, but due to strict firewall rules, this additional load meant that we started rejecting requests to our APIs in the European datacentre. The result of this was an outage for all our customers until we were able to update the firewall rules and get our US datacentre back online.
Obviously, this was a difficult situation, and it really made our transition to the cloud a high priority! We now have almost all our services running on the cloud, greater modularity in our architecture, and better automation in our stack. All this, coupled with better firewall rules, has meant we haven’t had a single significant issue on Black Friday since 2020!
The Future Technology Stack for Loqate
The past few years have seen considerable growth in our business in the Asia-Pacific region, not to mention increased traffic coming from the Americas. This has resulted in much more traffic flowing into our central US datacentre, as that is geographically the closest (and where traffic is routed for the Asia-Pacific region), but having requests travel that far can cause latency issues.
The simple solution to this problem would be to bring online another data centre, but that can be costly and would require maintenance. Until the business has enough traffic coming from that region, it makes financial sense to keep the traffic routed to the US, providing the latency is low enough.
The short-term plan for is to move the current US data centre to the east coast and set up another data centre on the west coast of the US, to lower the latency for most of the US and the Asia-Pacific region. This will give us better redundancy in one of our key markets, until we get more traffic coming from the Asia-Pacific region to justify the cost of setting up a dedicated data centre there.
We’re also looking at other options to improve latency for the Asia-Pacific region, such as using dedicated networks that some clouds provide. Take Google’s Premium network tier for example, which allows data packets to jump onto their private network near the source, then off near the destination allowing better latency. This is great but still wouldn’t completely solve the problem therefore the best solution is simply to bring online a new data centre when the business can justify the costs.
Hopefully this article has given you some insights into how we prepare for our busiest period of the year, and how some of what we do might be applicable to your technology business at particularly busy times of the year. You can find my talk regarding this topic on YouTube and the slides on slideshare and feel free to reach out to myself or our dev team on the Loqate Slack workspace if you have any questions.